Part four of four key developer skills.
Ability to immediately build a horizontally scalable solution without adding any special code for it in the first version.
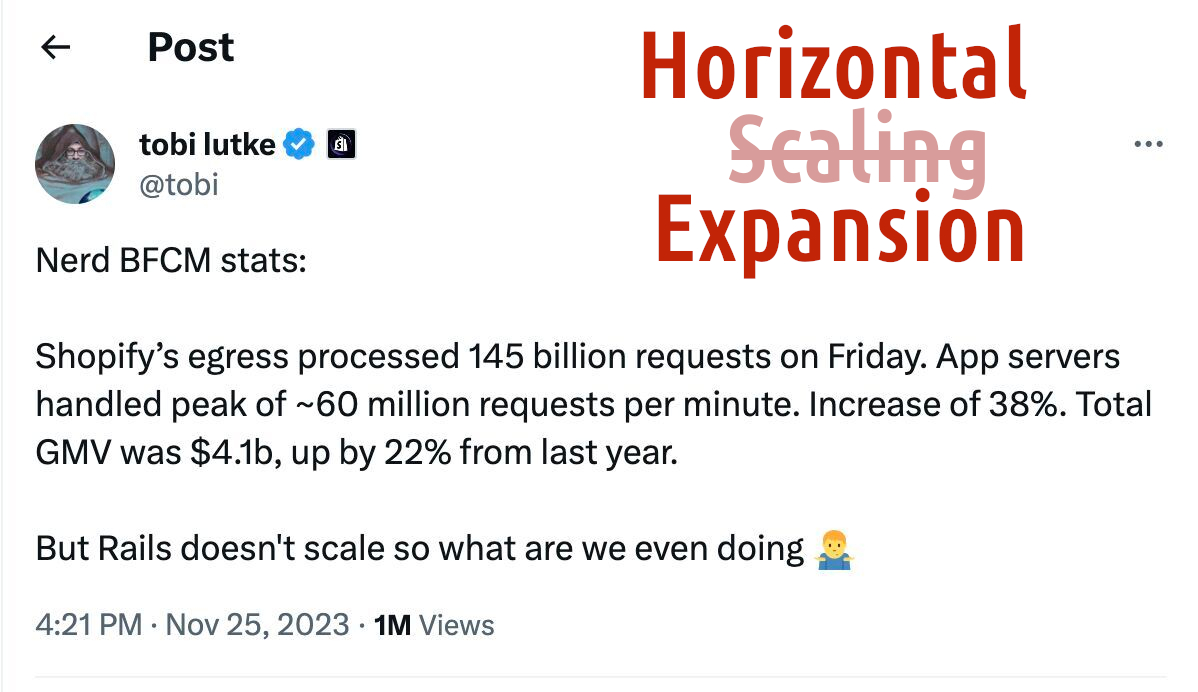
This turned out to be the hardest piece in the series, because literally a handful of developers actually understand what “horizontal scaling” is. Shown above is a screenshot of an amusing tweet by Tobi Lütke, which demonstrates either his supreme professionalism in sophistry, or his complete technical incompetence.
Serving ten billion clients does not mean your service is scalable. Buses carry people along Nevsky Prospect, and buses carry people along the Garden Ring; anyone who has completed three grades of parochial logistics school will tell you that speaking of “reliable connections between Leningrad and Moscow” on the basis of this incontrovertible fact is premature.
Even within a single city, the situation can easily spiral out of control. Scaling a bus fleet to match the expanding footprint of a metropolis is not about buying and deploying more buses. I lived in Berlin twenty years ago and could not stop marveling at how well the transport was organized. Judging by today’s passenger reviews, as the city spread outward—BVG did not cope.
I invite the thoughtful reader to pause here and think: so what exactly went wrong with the service’s scaling? For the superficial blockheads who can’t be bothered to think through what they’re reading—the answer is: logistics.
Deploying more buses onto the streets of a multi-million-person city doesn’t require much brainpower. But each individual passenger needs exactly one bus: the one that arrives immediately after they step off the previous one. Not an hour later, not a minute too early—within a three-to-five minute transfer window. As long as the bus schedule is built around minimized (and guaranteed) transfer times—we can speak of scaling. If bus A dumps its passengers at the terminal thirty seconds after connecting bus B has already pulled away—scaling has failed.
All right, to hell with Berlin—even with good public transport, living there was impossible. Let’s get back to Tobi.
Each Shopify user requires one persistent connection (a WebSocket) to one server. Adding new users is simply adding servers to the rack. If there are any scaling problems—they’re all clustered around the database, not Rails itself. Rails doesn’t care at all how many total servers are serving users: each server only needs to handle its own load.
This is not scaling. This is adding isolated capacity. It’s like if the zoom on your phone’s camera did not actually zoom in without unacceptable quality loss, but simply tiled more tiny copies of the image.
What the computing industry calls scaling is adding new hardware resources that increase the capacity of a connected node. Deploying more buses on new streets—no. Changing the schedule so that new buses coordinate with the existing ones—yes.
A chess server, for example, requires no scaling whatsoever. The server overheating?—Put another one next to it; in the end we’re serving disconnected pairs of players anyway. A server for the simultaneous slaughter of a billion sweaty nerds, on the other hand—that one needs scaling.
Let me briefly mention one example from personal practice before getting to the point. We process an incoming stream of currency exchange rates, perform some mathematical manipulations on them, and spit out peculiar results. Two hundred-plus currencies—that’s forty thousand pairs—with values arriving on average roughly once a second (in practice, more often). The mathematical manipulations can involve any number of currencies. All of this happens in real time. Because values must be available at any given moment, we cannot simply partition the pairs and split the streams across multiple servers. And a single server physically cannot handle it. Which means every node in the cluster must be able to exchange information with every other node—and the information is not static, so Redis won’t do. This is where the architecture needs the ability to scale horizontally.
The preamble has dragged on a bit. I hope I’ve at least clarified the terminology somewhat. So: if in the course of discussing an architecture you’ve concluded that the project will need genuine horizontal scaling—you cannot do without finite state machines. (In general it’s better to build all business logic on FSMs, but in a standalone system you can hobble along without them—in a cluster, there’s no way.) I rarely recommend reference material, but Introduction to the Theory of Computation by Michael Sipser is well worth a look. A finite state machine—for all its apparent simplicity—is something so powerful it genuinely astonishes.
Unfortunately, many believe that an FSM is simply a set of states—an extremely dangerous misconception that completely negates the entire body of formal mathematics upon which the power of finite state machines rests.
In any case, if you want to be ready to scale horizontally—build critical processes on finite state machines and make them fully asynchronous. If subsystem A must interact with subsystem B—forget about direct calls. In HTTP terms—201 is good, 200 is dreadful. Under no circumstances will you ever be able to later convert a request→response call sequence into request→acknowledgement→await response (without the destructive force of a complete refactor).
Asynchronous interactions built on top of FSMs, on the other hand, will make future scaling painless—because in this paradigm it makes absolutely no difference on which node the code handling a request actually runs.
There are languages in which this is easier (Elixir, Erlang), and those in which it’s harder. But in principle it is achievable in any environment. Once you get the hang of it, writing asynchronous code becomes no harder than synchronous. I speak from experience.
And finally, the perfect litmus test for determining whether your system is truly distributed or just a few servers standing in corners. If you’ve ever had to decide which letter from the CAP theorem set—‘C,’ ‘A,’ ‘P’—to sacrifice, you most likely have a genuine scalable cluster. If not—forget about horizontal scaling and simply add capacity as the business blooms.
And while I have the opportunity, I can’t resist recommending my own library Finitomata, which I prototyped in Idris and which is designed to be completely asynchronous (there is no way to determine from a response whether a state transition succeeded)—it provably prevents the programmer from violating a single law of finite state machine management.